FAIRplus indicators are designed for measuring data sets compliance
to Data Usage Areas. One indicator might support more than one Data
Usage Area. Indicators are grouped according to the ISA framework.
Study level documentation is available in a human readable format.
F+S02
Data is reported by following community specific minimum information guidelines
F+S03
Metadata documents and provides references about all data biological data types and formats in data is expressed.
F+S04
Relationships between different data sets in a study is well defined.
F+S05
A versioning policy is applied to uniquely identify a particular
form of a dataset from an earlier form or other forms of itself.
F+S06
Share not only derived and publication related data but data
generated in early phases of research data workflow such as primary data
and analyzed data.
F+S07
Negative results are shared.
F+S08
The study is described with metadata including context, samples and
data acquisition, methods for analyzing and processing data, quality
control, and restriction for reuse.
F+S08a
Metadata includes information about the study design, protocols and data collection methods.
F+S08b
Metadata includes explicit references to research resources such as samples, cell lines
F+S08c
Metadata contains information about data processing methods, data analysis and quality assurance metrics.
F+S08d
Metadata includes information about data ownership, license and reuse constraints for sensitive data.
F+A01
Data is organized and documented in a human understandable way
F+A02
Data is encoded in a community specific exchange standard.
F+A03
A machine and human readable formal description of the structure of data is available including types, properties.
F+A04
Data is structured by following a life sciences domain model, core
classes and their semantic relations refers to a common data model.
F+A05
Data is described with terminology standards.
F+A06
Core data classes (important data elements) follows a common master and reference data entity.
Study Level
F+S01 : Study level documentation is available in a human readable format.
Description
Study-level documentation provides high-level information on the
research context and design, the data collection methods used, any data
preparations and manipulations and summaries of findings based on the
data. Examples and a suggested list of coverage can be found at UK Data Services.
This
indicator does not require any machine interpretable content, or
semantic annotation of information with common vocabularies. It
measures, availability of information to help data users to make
informed use of the data. Publicly accessible web pages, pdf documents
are acceptable formats.
F+S02 : Data is reported by following community specific minimum information guidelines
Description
A reporting standard ensures recording the information (metadata)
required to unambiguously communicate experimental designs, treatments
and analyses, to con-textualize the data generated. Such standards are
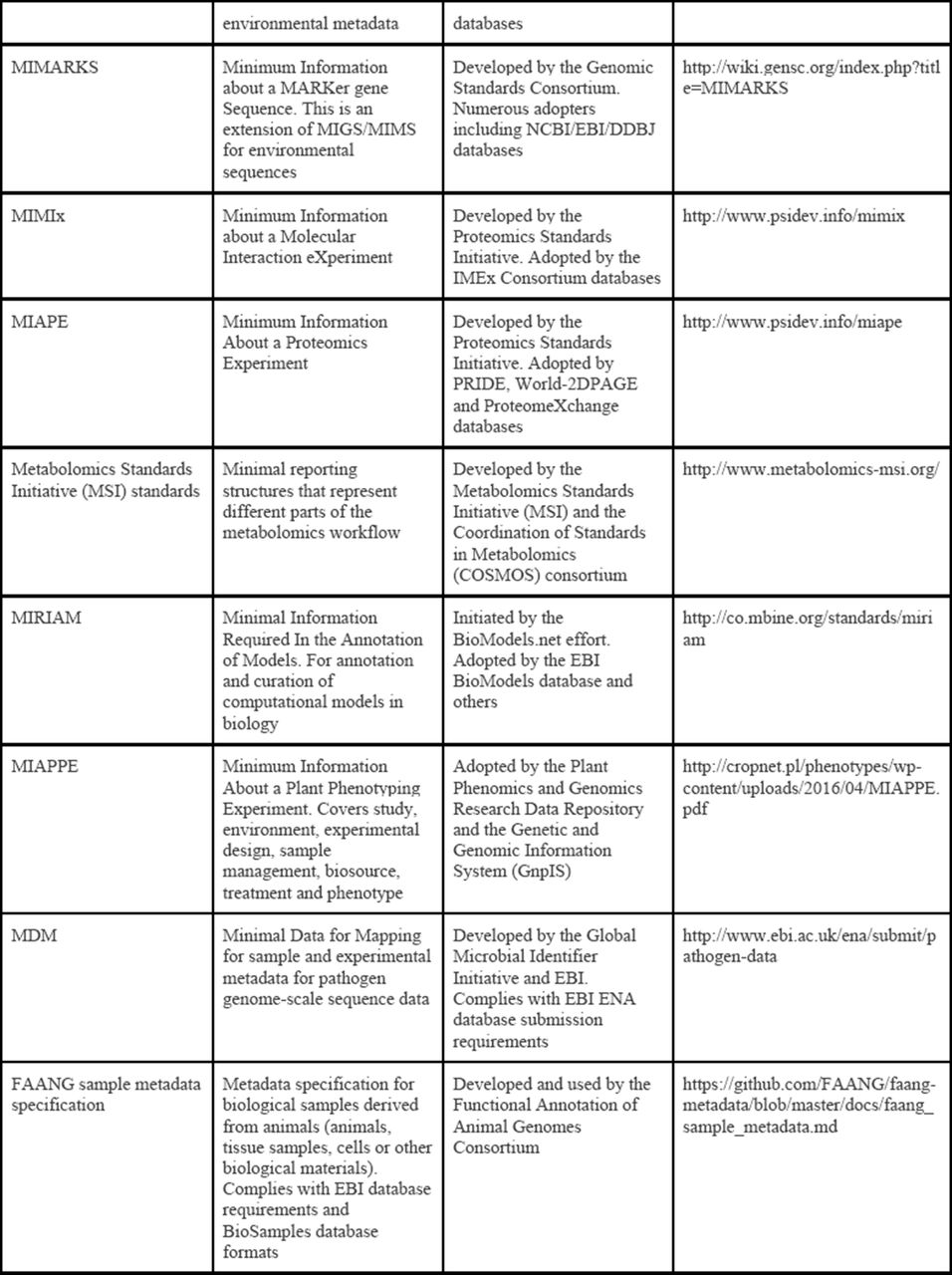
also known as data content or minimum information standards (Chervitz, et all.). See examples: reporting standards for health care, for life sciences data, collection of FAIRsharing
F+S03 : Metadata documents and provides references about all data biological data types and formats in data is expressed.
Description
Biological and biomedical research has been considered an especially
challenging research field in this regard, as data types are extremely
heterogeneous and not all have defined data standards (Griffin, et. all).
Metadata should capture all data types and format names in a study, if
possible provide a reference or URL for format specification, if not
possible have a description.
Example list of common standard data formats for omics data.
F+S04 : Relationships between different data sets in a study is well defined.
Description
In a study there are multiple data sets which are used as input and
produced as an output. When a data is FAIRified, it is important to
understand which data files are generated from the analysis of which
other data sets, or sample data. For example the EMBL-EBI SDRF (Sample
and Data Relationship Format) describes the sample characteristics and
the relationship between samples, arrays, data files. Some communities
such as proteomics have adopted these file formats to their needs, see SDRF for Proteomics . Furthermore, ISA allows multiomics support and is used by EMBL-EBI Metabolights
The relationships can be also expressed as naming a convention. A good example is the TCGA data
set, where the barcode contains semantic information about the relation
of data with other data (such as participant, sample, analyte, plate,
sample). If there is a naming convention used, instead of a defined
format standard, this convention should be clearly documented together
with code tables.
F+S05 : A
versioning policy is applied to uniquely identify a particular form of a
dataset from an earlier form or other forms of itself.
Description
Versioning is tracking the changes made in data by saving new copies
of data files with indicators of the changes made. A new version is
created when there is a change in the structure, contents, or condition
of the resource. In the case of research data, a new version of a
dataset may be created when an existing dataset is reprocessed,
corrected or appended with additional data. Versioned data are required
to cite and identify the exact dataset used as a research input in order
to support research reproducibility and trustworthiness (ANDS).
Best
practices of versioning should include a numbering system, information
about the status of the file, and what changes are made (see YALE
Research Data Management for the Health Sciences: File Versioning
involves tracking the changes,access older copies of files.)) . PIDs
can be assigned for versions, however there is no convention for that
(see ANDS : DOIs for versioned data). Some simple versioning solutions can be adopted (see Stanford libraries, Uni. Virginia Library).
F+S06 : Share
not only derived and publication related data but data generated in
early phases of research data workflow such as primary data and analyzed
data.
Description
Life science experiments comprise different samples; based on
experiment and sample, several measurements are performed. After
quantification there is a step of data processing and analysis which
results in life science research (Colmsee
et.all). In most cases, data is shared with publications as
supplementary files, or in data repositories which are referenced by
articles. However raw data and primary data resides in private storages (Arend,
et. all). There are great benefits of sharing primary data, including
to make meaningful comparisons between results, to answer ‘what if’
questions and to carry out pilot studies without repeating experiments (Koslow ).
This indicator measures availability of any primary data beyond the derived data or aggregated analyzed data.
Negative results are the outcomes which do not support study
hypotheses. Researchers are rewarded more for publishing novel findings,
and not for publishing negative results. However, sharing negative
results could reduce efforts and avoid repeating work that may be
difficult to replicate (ATCC).Negative result also can be reported in publications (e.g. Negative Results Journal).
This indicator measures the availability of negative results sets in the shared data content.
F+S08 : The
study is described with metadata including context, samples and data
acquisition, methods for analyzing and processing data, quality control,
and restriction for reuse.
Description
This indicator can be evaluated in two phases: 1) providing a
structured metadata with domain conventions; 2) providing machine
readable metadata by using any common vocabularies.
This indicator is divided into a set of indicators from F+S08a to F+S08d.
F+S08a : Metadata includes information about the study design, protocols and data collection methods.
Description
Example metadata: study / experiment design, trial protocol, data
acquisition methods, experiment methods, data processing methods . See multi omics metadata check list, clinical trial metadata
F+A01 : Data is organized and documented in a human understandable way
Description
Data-level, or object-level, documentation provides information at
the level of variables in a database or individual objects such as
images. Data-level information can be embedded in data files, such as
variable, value and code labels in an SPSS file or headers in a
document. Examples for quantitative, qualitative and secondary source
documentation can be found at UK Data Services.
This
indicator does not require any machine readable content, or semantic
annotation of information with common vocabularies. It measures how
easily data can be explored and understood by humans who are familiar
with the domain.
F+A02 : Data is encoded in a community specific exchange standard.
Description
A data exchange standard defined the encoding format of data. A data
exchange standard delineates what data types can be encoded and the
particular way they should be encoded (e.g., tab-delimited columns, XML,
binary, etc. They facilitate the exchange of information between
researchers and organizations, and between software programs or
information storage systems. ). They provide syntax standards but do not
specify what the document should contain in order to be considered
complete (Chervitz, et all.).
F+A03 : A machine and human readable formal description of the structure of data is available including types, properties.
Description
A schema describes the structure of the data. Special schemes have
meanings associated with databases, such as community agreed profiles. A
schema consists of a key dimension and its properties, expected types,
constraints, cardinalities and associated controlled vocabularies
(preferably refers to existing ontologies). Schemas and profiles can be
registered and reused, for examples FAIRsharing Standards and specific examples such as Schema.org, Bioschemas, or HL7 resources in the context of health data records.
F+A04 : Data
is structured by following a life sciences domain model, core classes
and their semantic relations refers to a common data model.
Description
Meaningful exchange of information is a fundamental challenge in
life sciences research. A domain model A domain is an abstract,
implementation-independent representation of the grammar, or semantics,
of a domain (Freimuth, et. all)
. Domain models define core classes and the semantic relationships
between them, as well as providing unambiguous definitions for concepts
required to describe life sciences research. Examples of life sciences
common data models are OMOP, BRIDG, Lifesciences DAM, functional genomics data modelling.
F+A05 : Data is described with terminology standards.
Description
Terminology standards is typically defined by the use cases and
provides control vocabularies to support and competency questions it is
designed to answer. In life sciences domain ontologies are common ways
to encode terminology standards (Chervitz, et all.).
Terminology standards add an interpretive layer to the data by defining
the concepts or terms in a domain, and in some cases the relationships
between them (Tenenbaum et. all). See an example list for terminology standards. For a complete listing see the OBO Foundry.
F+A06 : Core data classes (important data elements) follows a common master and reference data entity.
Description
Master data is defined as core business objects used in different
applications across an organization along with their associated
metadata, definitions and taxonomies. Reference data is used to
characterize or classify other data such as codes and description
tables. Master and Reference data lowers cost and complexity through use
of standards, common data models, and integration patterns. Sharing
master data within a community or in organization reduces variability
caused by multiple studies producing the same type of data, but in
isolation, then inconsistencies in data structure and data values
between the systems occurs (DAMA). In the life science domain,
master data entities examples can be a study, a subject, a file, a
chemical compound, or an observation. Common data models provide core
classes which can be useful for creating master data elements (see LS DAM Experiment,
Molecular Biology, Molecular Databases core classes). However master
data should be described, are assigned an unique identifier, and
registered on a searchable source. An example to reference data from the
health domain can be the value set of the HL7.
Precondition
of measuring this indicator is the existence of a master and reference
data in a related research community, an organization, or a repository.

{kind=link}